![]()
2017CV技术报告:从3D物体重建到人体姿态估计
时间:2017-12-12 01:55 点击:次
原标题:深度 | 2017CV技术报告:从3D物体重建到人体姿态估计
选自The M Tank
机器之心编译
The M Tank 编辑了一份报告《A Year in Computer Vision》,记录了 2016 至 2017 年计算机视觉领域的研究成果,对开发者和研究人员来说是不可多得的一份详细材料。该材料共包括四大部分,在本文中机器之心对第三部分做了编译介绍,第一部分、第二部分和第四部分详见《计算机视觉这一年:这是最全的一份 CV 技术报告 》、《深度 | 2017 CV 技术报告之图像分割、超分辨率和动作识别 》、《计算机视觉这一年:2017 CV 技术报告 Plus 之卷积架构、数据集与新趋势 》。
「计算机视觉的主要目标是从 2D 的观察复原世界的 3D 结构。」――Rezende et al. (2016, p. 1[92]
正如我们所了解的,在计算机视觉领域,对场景、物体和活动的分类以及绘制边界框和图像分割是许多新兴研究的重点。实际上,这些方法依靠计算来「理解」图像的二维空间。但是,反对者指出,理解 3D 空间对于系统地解释和认知现实世界是必不可少的。
例如,一个网络可能会在图像中找到一只猫,将猫的灰度图上色,并将其归类为一只猫。但是,网络是否能完全理解图像里的猫在其所处环境中的位置?
可能有人会说,在上述任务中,计算机对于 3D 世界的了解很少。与此相反,即使在查看 2D 图片(即透视、遮挡、深度、场景中的对象如何相互关联等情况下)的时候,人们也能够以 3D 空间来理解世界。将这些 3D 表示及其相关知识传递给智能系统是下一场计算机视觉变革的前沿。我这样想的一个主要原因是:
「场景的 2D 投影是关于摄像机的位置、属性,以及灯光和组成场景的物体的复杂函数。如果赋予 3D 理解,智能体可以从这种复杂性中抽象出稳定的、易懂的表示。例如,无论是从上面还是从侧面看,在不同的光照条件和遮挡情况下,模型都可以辨认出椅子就是椅子。」[93]
但是,理解 3D 空间一直面临着几个难题。第一个问题涉及到「自遮挡」和「正常遮挡」的问题,以及大量 3D 形状都能符合单个 2D 表示的特征。由于无法将相同结构的不同图像映射到相同的 3D 空间以及处理这些表示的多模态,对这些问题的理解变得更加复杂 [ 94 ]。最后,实况的 3D 数据集通常相当昂贵且难以获得,加上表示 3D 结构的方法各异,这些都导致了模型训练的局限性。
3D 物体
第一部分有些零散,仅作为一个概览,涉及应用于 3D 数据表示的物体的计算、从 2D 图像推导 3D 物体形状和姿态估计、从 2D 图像确定物体的 3D 姿态的变换。[95] 重建的过程将在下一节中详细地介绍。以下展示了我们团队在这个综合领域的最激动人心的工作:
OctNet: Learning Deep 3D Representations at High Resolutions[96] 紧接最新的卷积网络研究进展(即对 3D 数据、体素(voxel)进行 3D 卷积操作)。OctNet 是一种新颖的 3D 表示形式,可以使高分辨率的输入的深度学习变得容易。作者通过'分析分辨率对包括 3D 对象分类、方向估计和点云标记在内的多种 3D 任务的影响'来测试 OctNet 表示。本文的核心贡献是它利用 3D 输入数据的稀疏性,从而能够更有效地使用内存及计算。
ObjectNet3D: A Large Scale Database for 3D Object Recognition[97] 贡献了一个数据库,用于 3D 物体识别,其中包含 100 个物体类别的 2D 图像和 3D 形状。『我们的数据库中的图像(取自 ImageNet)中的对象与(从 ShapeNet 存储库获取)的 3D 形状保持一致,该一致性指为每个 2D 物体提供精确的 3D 姿态标注和最接近的 3D 形状标注。』 基准实验包括:生成区域建议、2D 物体检测、联合 2D 检测和 3D 物体姿态估计,以及基于图像的 3D 形状恢复。
3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction[98] - 使用任意视角的单个或多个对象实例的图像,以 3D 占据网格的形式重建对象,主要利用合成数据学习从物体 2D 图像到 3D 形状的映射,网络不需要任何图像标注或物体类别标签就可以训练和测试。该网络由一个 2D-CNN、一个 3D 卷积 LSTM(为本文需要新创建的结构)和一个 3D 解卷积神经网络组成。这些不同的组件之间的相互作用和联合端到端的训练是神经网络分层特征的完美例证。
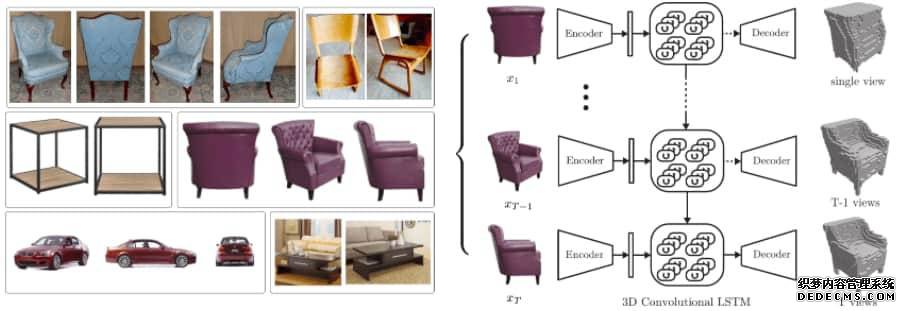
图 11: 3D-R2N2 的功能图例
论文笔记:作者希望重建的一些示例对象图像――视图被高基准分隔开,并且物体的外观纹理很少或是非朗伯表面,亦或两者具备。(b)对我们提出的 3D-R2N2 的概述:网络从任意(未校准的)视角输入一系列图像(或者一张图像)作为输入(在本例中为扶手椅的 3 个视图),并产生重建的体素化 3D 作为输出。随着网络看到对象的更多视图,重建过程逐渐细化。
3D-R2N2 使用 ShapeNet 模型生成渲染图像和体素化模型,并有助于 3D 物体重建,而从运动恢复结构(SfM)和并发建图与定位(SLAM)通常会失败:
「我们的拓展实验分析表明,我们的重建框架(i)优于最好的单一视图重建方法,并且(ii)当传统的 SFM / SLAM 方法失效时,仍然能够对物体进行三维重建。
3D Shape Induction from 2D Views of Multiple Objects[100] 使用投影生成对抗网络(PrGANs)训练一个可以准确表示 3D 形状的深度生成模型,其中判别器仅显示 2D 图像。投影模块捕获 3D 表示,并在传递给判别器之前将其转换为 2D 图像。通过迭代训练周期,生成器通过改进生成的 3D 体素形状来完善投影结果。
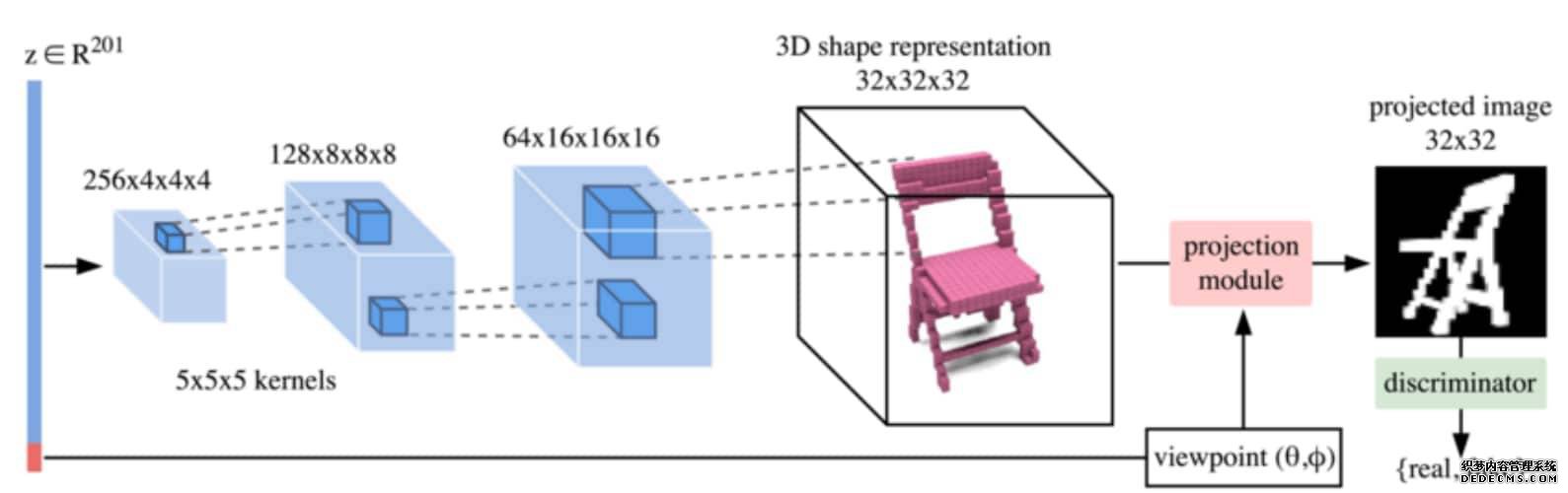
图 12:PrGAN 部分架构